MySql调优
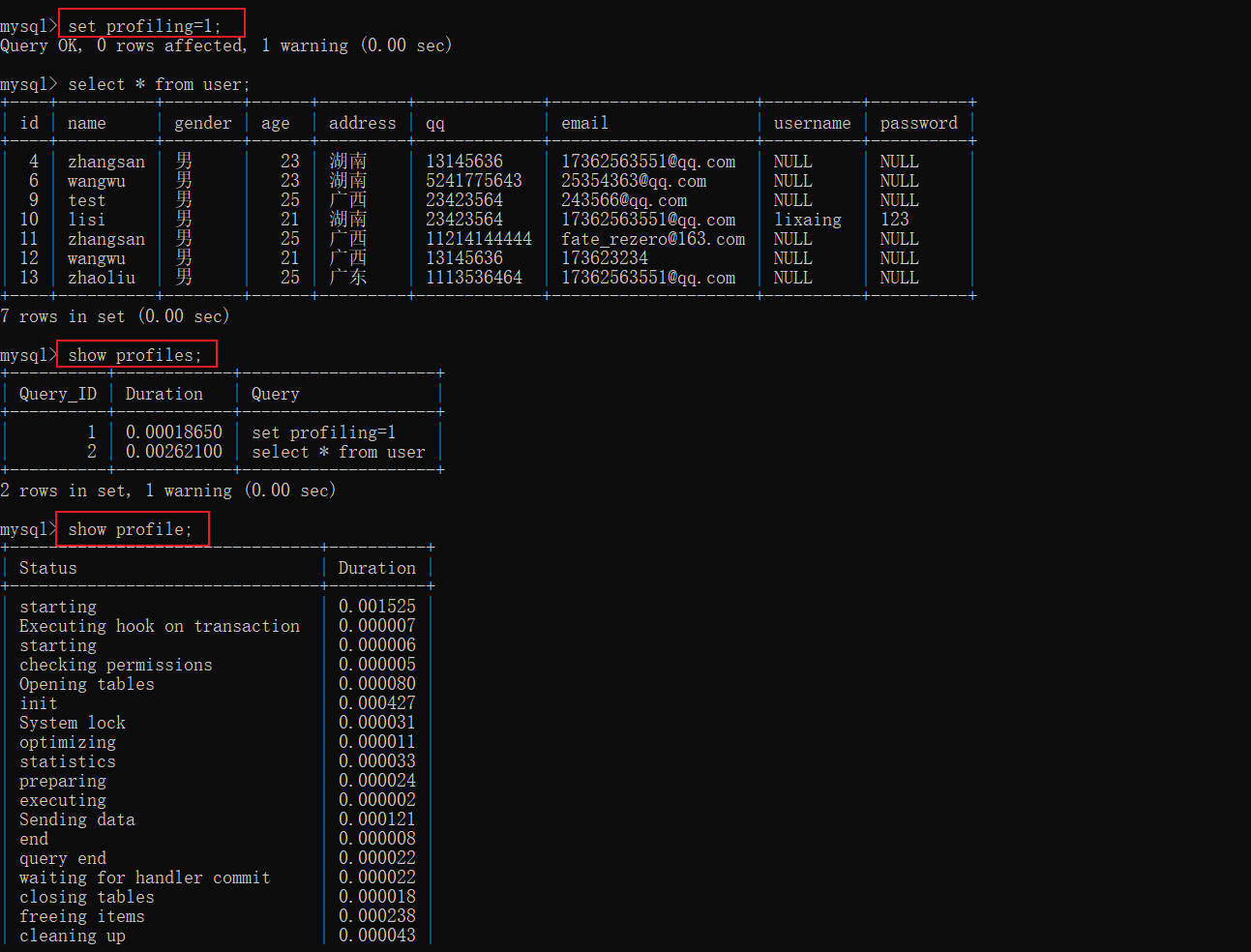
show profiles
- 查看SQL各阶段的执行时间,可以具体到SQL的哪个点执行慢;
performance_schema
作用:监控当前这台服务器上面MySql的一些性能使用情况,我们一般说性能的时候,不能说只看SQL语句,这不对,
需要直到当前这条SQL语句耗费了多少cpu资源,耗费了多少IO资源,耗费多少内存资源
show processlist
- 使用show processlist查看连接的线程个数,来观察是否有大量线程处于不正常的状态或者其他不正常的特征;
索引优化细节
- 隐式类型转换导致走不上索引
- 实测count(1)和count(※)效率一样,可以使用show status like ‘last_query_cost’查看两者的执行成本
- order by和groupby的列尽量建索引,确保任何的order by和groupby中的表达式只涉及到一个表中的列,这样mysql才有可能使用索引来优化这个过程
- 优化子查询,子查询的优化最重要的优化建议是尽可能使用关联查询代替,子查询会产生临时表,但是这里替换成关联查询的效率不一定效率会更高,还是需要根据实际情况对两条SQL进行分析,提出这一点的目的是为了在实际生产中能够保持优化的习惯,更多的去对比多种查询方式所带来的实际效果
关联查询优化
Simple Nested-Loop Join
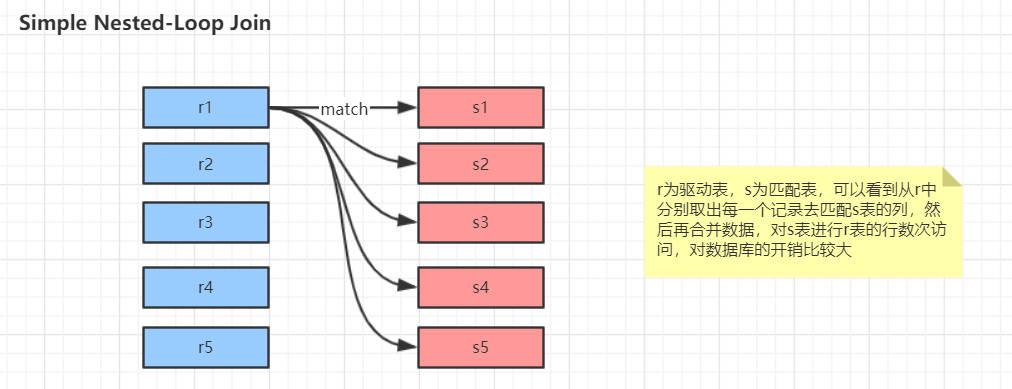
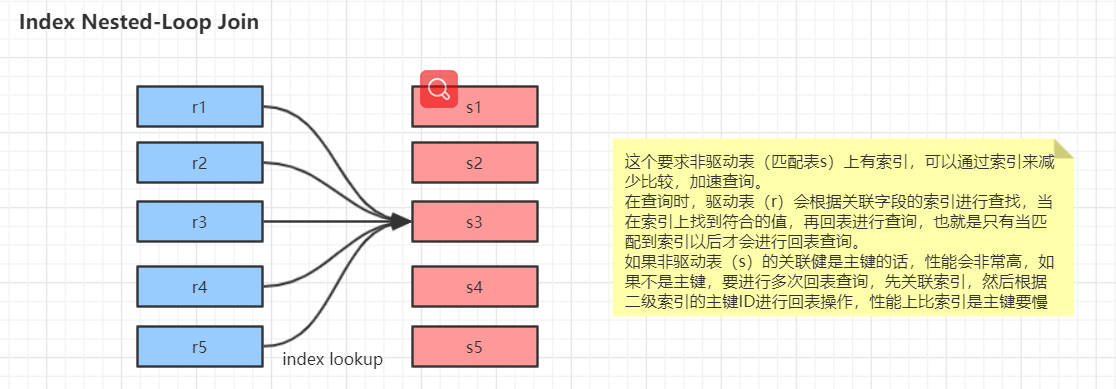
Index Nested-Loop Join
Block Nested-Loop Join
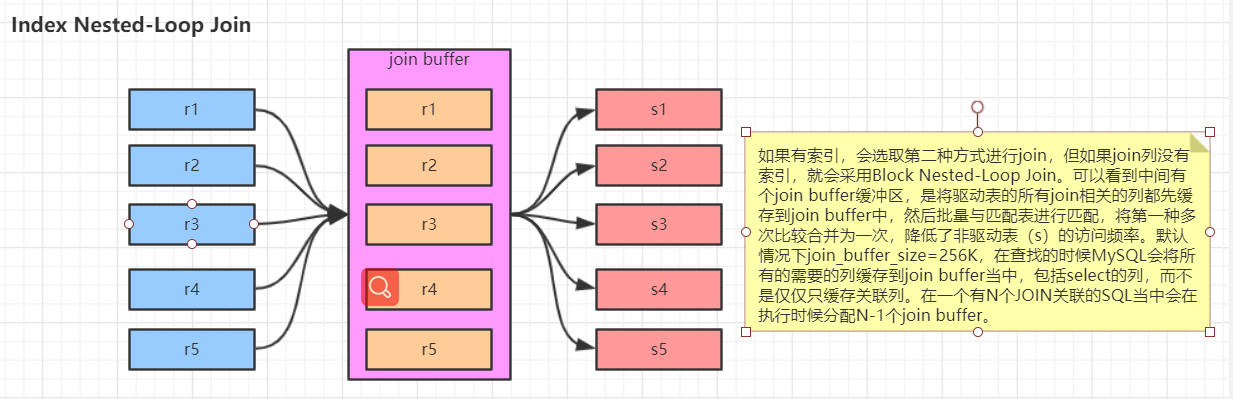
(1)Join Buffer会缓存所有参与查询的列而不是只有Join的列。
(2)可以通过调整join_buffer_size缓存大小
(3)join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
(4)使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
(5)show variables like ‘%optimizer_switch%’查看不同的顺序执行方式对查询性能的影响:
1
2
3
4
5
6
7
8
9
10
11
12
13explain select film.film_id,film.title,film.release_year,
actor.actor_id,actor.first_name,actor.last_name
from film inner join film_actor using(film_id)
inner join actor using(actor_id);
查看执行的成本:
show status like 'last_query_cost';
按照自己预想的规定顺序执行:
explain select straight_join film.film_id,film.title,film.release_year,
actor.actor_id,actor.first_name,actor.last_name
from film inner join film_actor using(film_id)
inner join actor using(actor_id);
查看执行的成本:
show status like 'last_query_cost';
排序优化
理解:无论如何排序都是一个成本很高的操作,所以从性能的角度出发,应该尽可能避免排序或者尽可能避免对大量数据进行排序。
推荐使用利用索引进行排序,但是当不能使用索引的时候,mysql就需要自己进行排序,如果数据量小则在内存中进行,如果数据量大就需要使用磁盘,mysql中称之为filesort。
如果需要排序的数据量小于排序缓冲区(show variables like ‘%sort_buffer_size%’;),mysql使用内存进行快速排序操作,如果内存不够排序,那么mysql就会先将树分块,对每个独立的块使用快速排序进行排序,并将各个块的排序结果存放再磁盘上,然后将各个排好序的块进行合并,最后返回排序结果
排序算法
- 两次传输排序:第一次数据读取是将需要排序的字段读取出来,然后进行排序,第二次是将排好序的结果按照需要去读取数据行。
两次传输的优势,在排序的时候存储尽可能少的数据,让排序缓冲区可以尽可能多的容纳行数来进行排序操作,但增加第二次读取数据的IO成本 - 单次传输排序:先读取查询所需要的所有列,然后再根据给定列进行排序,最后直接返回排序结果,此方式只需要一次顺序IO读取所有的数据,而无须任何的随机IO,问题在于查询的列特别多的时候,会占用大量的存储空间,无法存储大量的数据
- 当需要排序的列的总大小超过max_length_for_sort_data定义的字节,mysql会选择双次排序,反之使用单次排序,当然,用户可以设置此参数的值来选择排序的方式