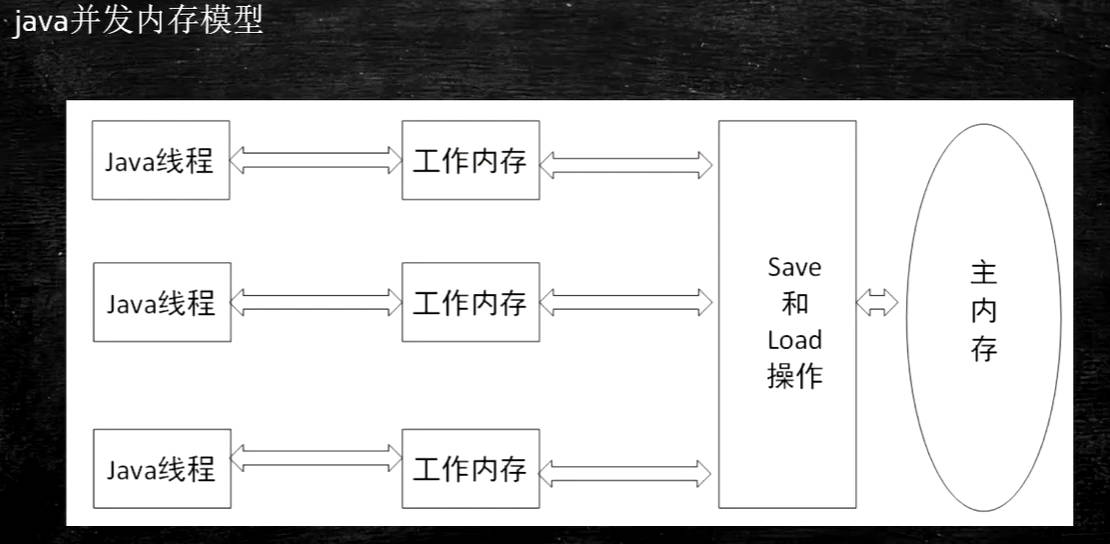
Java内存模型
存储器的层次结构
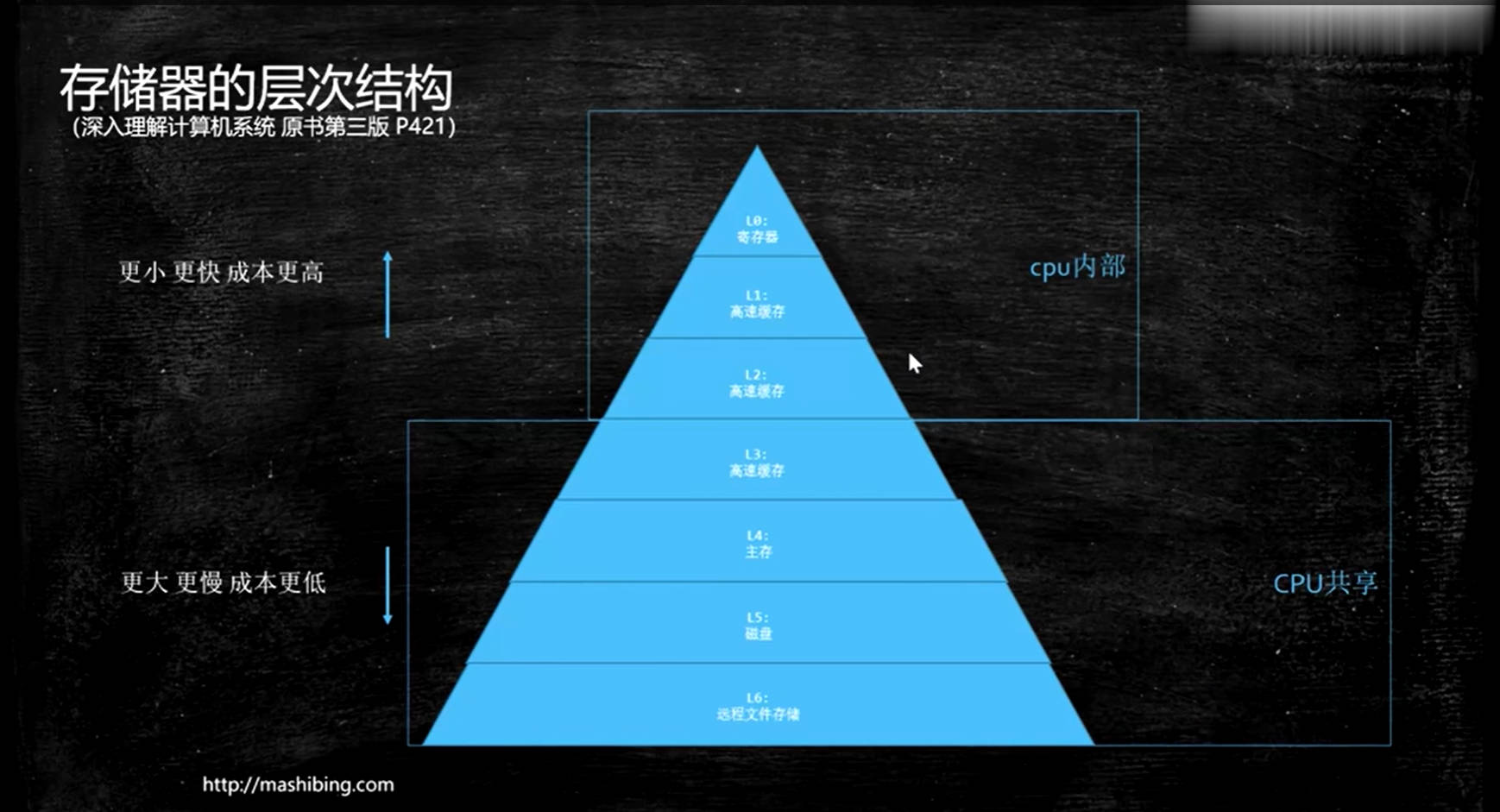
- 理解:cpu的存储和获取数据的速度相较于内存的速度要大约快上百个数量级,内存相较于硬盘要快上百个数量级,如果对存取速度比较高的时候,就可以将数据放在内存里,如果要求更快的话,可以将数据放在高速缓存里,但是即使是高速缓存(L3)相对于cpu来说也是非常慢的,其实在cpu内部还有两层高速缓存(L1和L2),所以cpu在读数据的时候会先去高速缓存L1找,cpu从高速缓存中取数据非常快,如果L1中没有就回去L2中找,在没有就会去分别去L3,内存或者硬盘中找,找到后放入高速缓存中,下次取数据时直接从高速缓存中拿;
- 注意:从存储器的层次结构可以了解到,最终cpu读取数据后会将数据缓存在L1和L2中,而每个cpu都有自己的高速缓存L1和L2,也就是主存或者L3中的数据会被加载到不同的cpu中,如果第一个cpu把某一个数据改为了1,另一个cpu把该数据改成了2,这时候就会存在数据不一致的问题
多线程一致性硬件层的支持
- 早期的cpu采用总线锁来解决这种数据不一致的问题,具体可以解释为某个cpu访问主存中的数据,就会给总线上一把锁,相当于在cpu和主存之间建了一道屏障,来使其他cpu此时不能操作同一份数据来达到数据一致,存在明显的缺陷,因为是对总线加锁,其他cpu同时也不能访问其他数据了,极大的影响了效率;
- 各种cpu厂商采用了各种各样的缓存一致性协议
intel的cpu使用的MESI缓存一致性协议
MESI:分别指四种状态,cpu缓存行(caceh line)标记四种状态
1.Modified(被修改):如果某个缓存行被某个cpu被修改过且只缓存在该CPU中,即与主存中的数据不一致,则将缓存行标记为Modified,该缓存行中的内存需要在未来的某个时间点写回主存。
2.Exclusive(独享的):该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。
3.Shared(共享的):该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。
4.Invalid(无效的):该缓存是无效的(可能有其它CPU修改了该缓存行)。
- 注意:虽然缓存一致性协议的效率比总线锁要高的,但是缓存一致性协议并不能满足所有场景保证一致性,比如:有些无法被缓存的数据,或者跨越多个缓存行的数据,无法使用缓存一致性协议,依然必须使用总线锁;现代CPU的数据一致性实现 = 缓存锁(MESI …) + 总线锁
缓存行
- 理解:当cpu把某个数据读取到缓存中时,比如读取某个int类型的值,它并不是只是把这个int类型的值读取进缓存,而是把int数据所在的64字节的内存块读取进缓存,我们把这个64字节的内存块作为基本单位,称之为缓存行;(这个缓存行目前多数cpu厂商设置为64字节)
- 硬件的设计上很多时候是按块来执行的,并不是一个字节一个字节来执行的,处理整个块会更加方便且在很多时候会更高效;
伪共享
- 理解:同一个缓存行中同时有a和b两个数据,cpu1需要使用x,读取缓存行到自己的缓存中,cpu2需要使用y,同样也需要读取缓存行到自己的缓存中,这时如果cpu1修改x,就需要将cpu2的缓存行标记为Invalid失效的,cpu2就需要去主存中重写读取数据,同理cpu2如果修改了y数据,同样也会将cpu1的缓存行标记为Invalid,cpu1也会去主存中重新读取数据,但是实际上cpu1是不需要知道y数据的状态,cpu2也不需要知道x的状态,但是上面说的情况却让他们共享x,y数据,从而产生伪共享;
- 一句话总结一下:位于同一缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题
使用缓存行的对齐提高效率
1 | public class CacheLinePadding { |
指令重排序
- CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),同时也会执行另一条指令,前提是,两条指令没有依赖关系,这种方式在单线程环境下可以提高cpu的执行效率,但是在多线程环境就会存在数据不一致的问题;
- 虽然可以指令重排序,但并不意味可以随便排序,在JVM规范中规定了重排序必须遵循:
1.hanppens-before原则
2.as-if-serial 语义:不管如何重排序,单线程的执行结果不会改变 - 这两条原则的规范,具体的实现还要看各大JVM厂商的具体实现;
指令重排序证明
1 | public class Disorder { |
合并写
- CPU除了指令重排序之外,还对数据写入高速缓存L2进行了优化,添加了Write Combining Buffer,一般是4个字节,在写入L1的同时,也会写入WC Buffer,满了之后,再直接更新到L2
###为什么需要合并写技术
由于CPU的ALU算算术逻辑单元的处理速度非常快,而将数据写入到高速缓存L2的速度相对来说非常慢,所以添加了Write Combining Buffer,将数据先写入合并写缓冲区,满了之后再一次性写入到L2;
利用合并写技术提高程序执行效率
1 | public final class WriteCombining { |
硬件级别保证有序
硬件内存屏障 X86:
sfence: 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序JVM级别内存屏障如何规范(JSR133)
LoadLoad屏障: 对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕;
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见;
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕;
StoreLoad屏障: 对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见;
volatile实现细节
- 字节码层面
会在对应的volatile标记的变量前加上访问标识符:0x0040 [volatile]:ACC_VOLATILE(可以通过Jclasslib查看字节码) - JVM层面
(1)对于所有的volatile变量的写操作,前面加上StoreStoreBarrier,volatile写,后面加上StoreLoadBarrier
(2)对于所有的volatile变量的读操作,前面加上LoadLoadBarrier,volatile读,后面加上LoadStoreBarrier - OS和硬件层面
上述只是JVM规范中这样加上内存屏障,硬件底层也会有一些指令来完成volatile的实现:
hsdis - HotSpot Dis Assembler (HotSpot虚拟机的反汇编,这个工具是观察虚拟机编译好的那些字节码,在cpu级别到底使用什么样的汇编指令来完成的)在windows下是使用lock前缀指令实现的;
lock前缀指令在cpu级别做了什么
- 在早期的cpu中,lock前缀指令会进行显式的总线锁定;通过这种机制来达到数据一致;
- 随着技术的发展及缓存一致性协议的应用,当数据满足被单个缓存行缓存的时候,Lock前缀指令会遵循缓存一致性协议给对应的缓存行标记上对应的状态,以MESI为例,分别对应着四种不同的状态,Modified(被修改),Exclusive(独享的),Shared(共享的),Invalid(无效的)分别对应的不同的处理方式,如果数据不满足被单个缓存行缓存的时候,lock前缀指令会进行显式的总线锁定;通过这种机制来达到数据一致;
synchronized实现细节
- 字节码层面
synchronized方法:访问标识符标记为0x0020 [synchronized]:ACC_SYNCHRONIZED
synchronized代码块:monitorenter、monitorexit、monitorexit,注意这里为什么会有两个monitorexit,是因为一个发生异常退出,另一个是代码块正常执行完毕退出; - JVM层面
(1).在HotSpot虚拟机中,Monitor底层是由C++实现的,它的实现对象是ObjectMonitor.
(2).ObjectMonitor对象的主要属性如下:
_count:记录该线程获取锁的次数(也就是前前后后,这个线程一共获取此锁多少次);
_recursions:锁的重入次数;
_owner:The Owner拥有者,是持有该ObjectMonitor(监视器)对象的线程;
_EntryList:EntryList 监控集合,存放的是处于阻塞状态的线程队列,在多线程下,竞争失败的线程会进入 EntryList 队列;
_WaitSet:WaitSet 待授权集合,存放的是处于 wait 状态的线程队列,当线程执行了 wait() 方法之后,会进入 WaitSet 队列;
(3).监视器执行的流程如下:
1.线程通过 CAS(对比并替换)尝试获取锁,如果获取成功,就将 _owner 字段设置为当前线程,说明当前线程已经持有锁,并将 _recursions 重入次数的属性 +1。如果获取失败则先通过自旋 CAS 尝试获取锁,如果还是失败则将当前线程放入到 EntryList 监控队列(阻塞);
2.当拥有锁的线程执行了 wait 方法之后,线程释放锁,将 owner 变量恢复为 null 状态,同时将该线程放入 WaitSet 待授权队列中等待被唤醒;
3.当调用 notify 方法时,随机唤醒 WaitSet 队列中的某一个线程,当调用 notifyAll 时唤醒所有的 WaitSet 中的线程尝试获取锁;
4.线程执行完释放了锁之后,会唤醒 EntryList 中的所有线程尝试获取锁; - OS和硬件层面
X86 : lock cmpxchg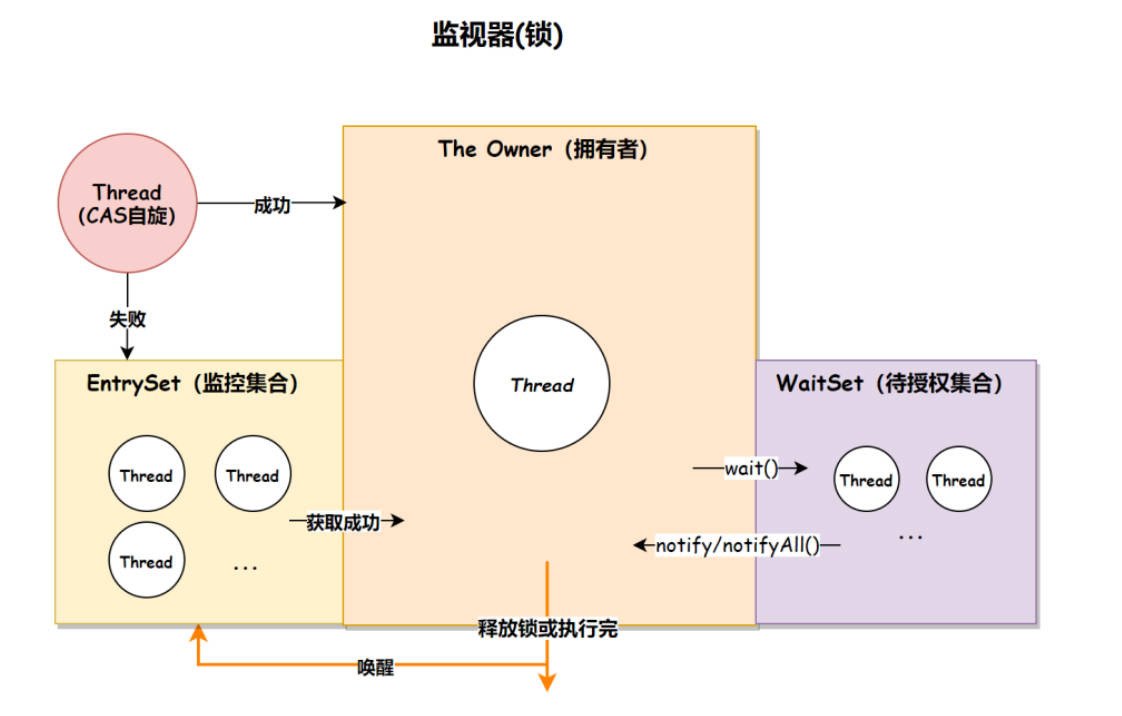
Java并发内存模型