MySql数据结构
MySql数据结构选择
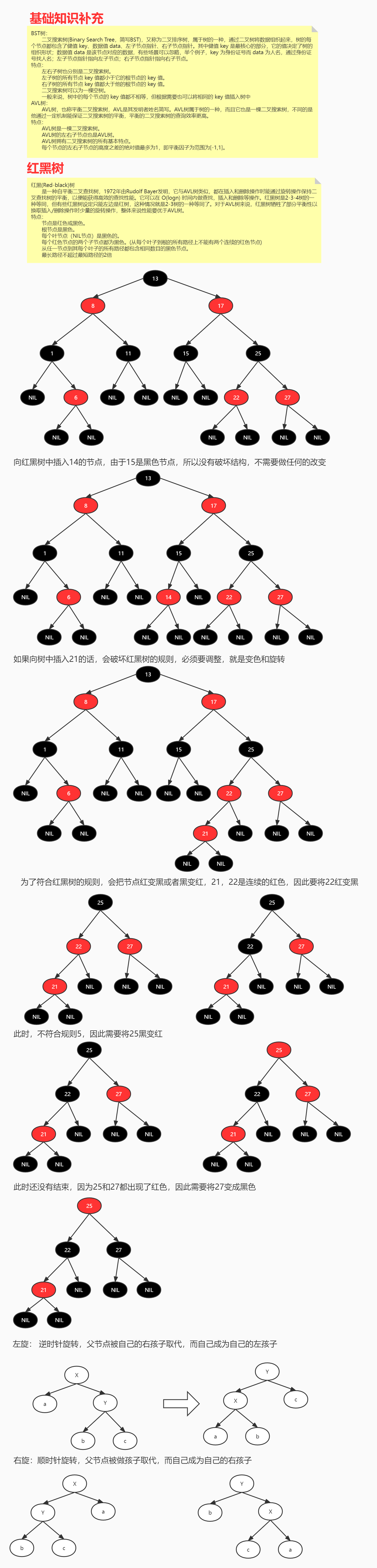
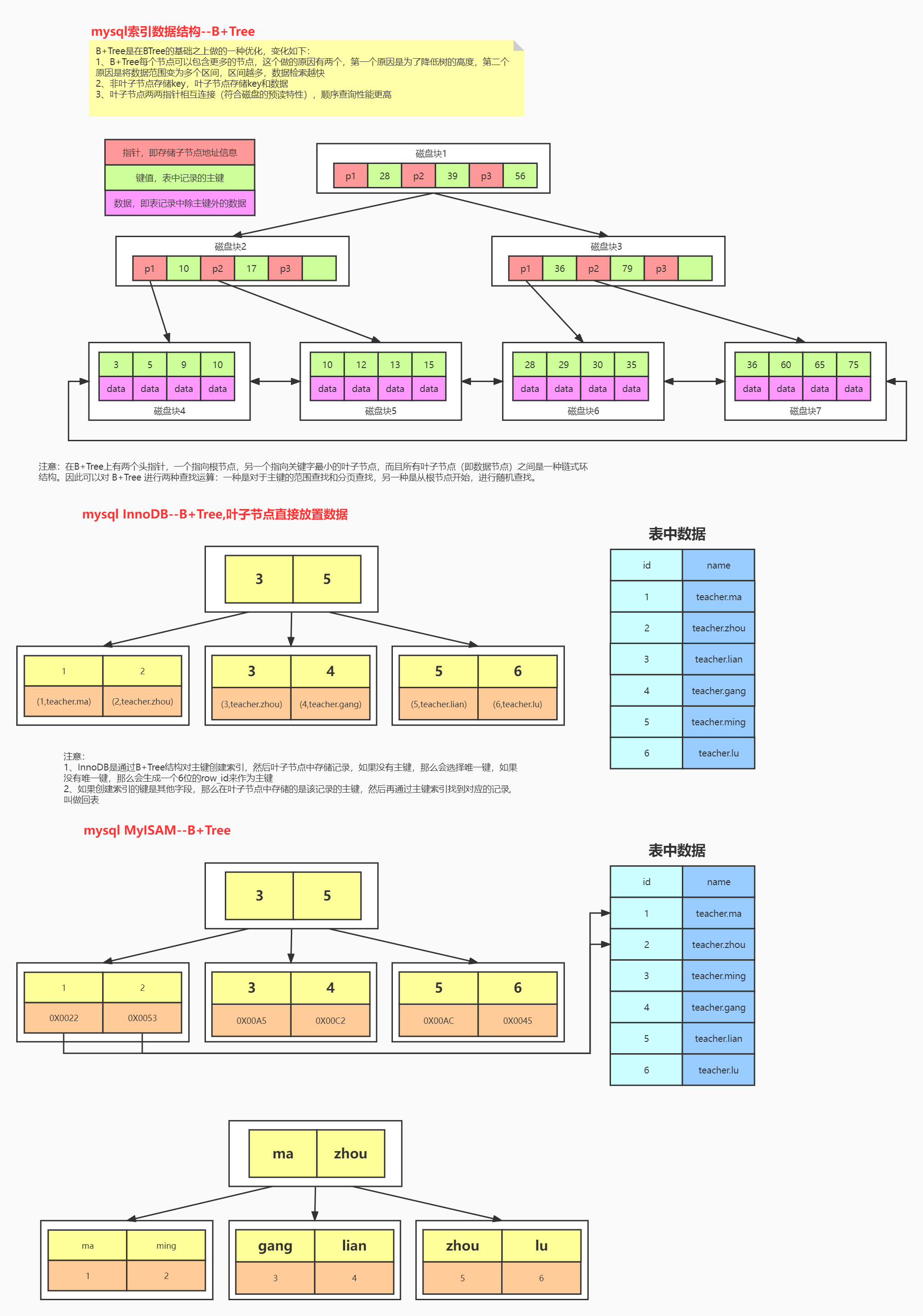
为什么不使用B树而采用B+树
B树和B+树的主要区别:
1.B的数据分布在所有节点之上,而B+树的数据都是分布在叶子节点上,非叶子节点存储都是key和子节点地址信息;
2.B+最下层两个节点之间有双向指针,能够更好的支持范围查询;
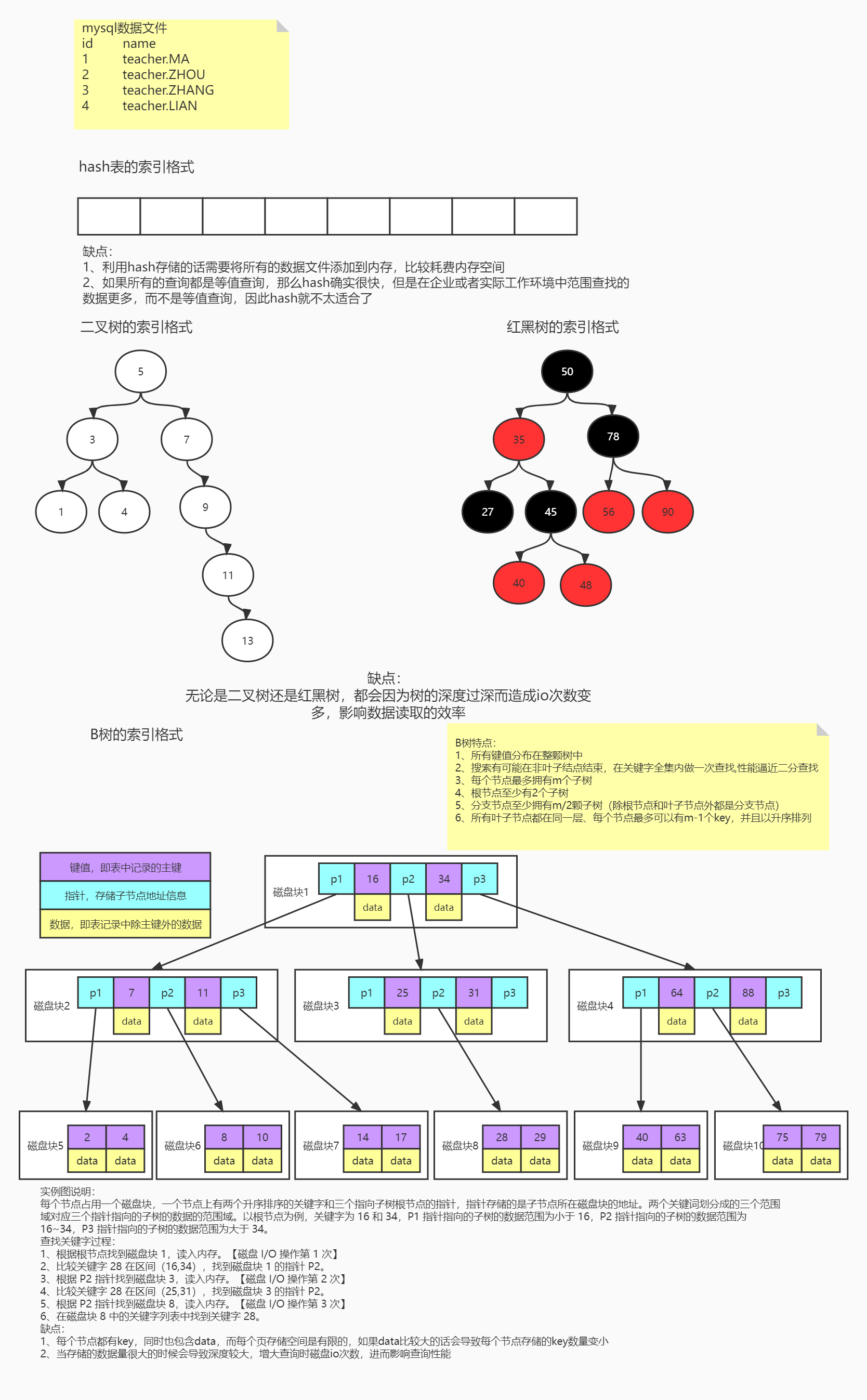
知识储备:MySql在读取数据的时候采用的是磁盘预读;
磁盘预读的好处:
1.当某个数据库操作,数据库需要从磁盘上频繁读取数据的时候,会产生相对较多的IO等待,影响性能;
2.为了避免这个情况,数据库采用了预读的机制,也就是当读取的内存中还有若干页需要处理的时候就开始触发磁盘预读,而且是预读若干连续的数据页,从而提高效率
Linux默认页大小4kb
Mysql默认的innodb_page_size:16KB
在默认情况下,MySql每次最多读取4页数据进内存,如果data分布在所有节点上,这里我们可以做一个估算,假设每个data数据 + key + 字节点地址信息的大小为1KB,这样一次只能读取16条数据进内存,假设B+树为3层,只能支撑4096条数据
而采用B+树,非叶子节点只存储key和子节点地址信息,假设每个key + 字节点信息为10个字节,这样一次就能读取1600左右的key进入内存,这样可以得出3层B+树就可以支撑百万级到千万级得数据量
好处:
MySql存储引擎
InnoDB存储引擎:数据和索引是存放在一个文件的
MyISAM存储引擎:数据和索引是分开存放的
两者索引存储的数据结构都是采用的B+树
这种分开和放在一起存放方式就决定了最终我们在查找数据节点的查找方式是不一样的
InnoDB的叶子节点所存储就是我们实际上的一整行数据;
MyISAM的叶子节点所存储只是我们实际一整行数据所对应的地址,然后根据地址去myd文件里找到实际的数据
InnoDB是通过B+树结构对主键创建索引的,然后叶子节点中存储记录,如果没有主键,那么会选择唯一键,如果没有唯一键,那么它会生成一个6位的row_id作为主键
主键索引
唯一索引
普通索引
全文索引
组合索引
回表
比如说使用name列创建索引,当我们使用name去查询数据的时候,会先查询使用name构建的B+树索引结构,获取到那么所对应的叶子节点,然后获取到叶子节点对应数据的主键,再根据主键去查询主键对应的B+树索引结构,在获取到叶子节点中整行的数据;此时就称之为回表
覆盖索引
- 创建一个索引,该索引包含查询中用到的所有字段,称为”覆盖索引”
- 还有一种特殊情况,当创建了非主键索引,但是我们只查询主键的时候,同样可以称之为”覆盖索引”,因为非主键索引去查询数据时,是会先去查询自己的B+树索引结构,获取到叶子节点的主键,由于这里只需要查询主键,所以不需要回表,所以这种情况也是覆盖索引;
最左匹配原则
当我们项目有大量的查询同时用到name和age来进行查询,此时可以创建name和age的组合索引,
select * from emp where name = ? AND age = ? //走的上索引 — 这里查询优化器会自动优化查询顺序,name和age更换位置也可以
select * from emp where age = ? // 走不上索引
select * from emp where name = ? // 走的上索引
必须先有最左边,索引才能走的上,所以这里我们在建立索引的时候需要根据字段查询优先级来决定创建索引时的顺序
这里创建索引有两种方案:
1.name_age和age;
2.age_name和name;
在大多数情况下第一种是更好的,因为我们的索引也需要占存储空间,如果使用age所占的存储空间相对来说要更小点的;
在高版本MySql中是优化器是支持索引合并的;
索引下推
在MySql5.6之前,我们建立联合索引,是无法使用到索引下推的,比如说我们建立name和age的组合索引,当我们的查询语句是where name = ‘’ AND age = ‘’;Mysql首先是会通过索引找到所有name的匹配的叶子节点对应的主键id,然后通过主键id回表查询到叶子节点对应的整行数据,然后交给mysql的server层处理,server层会将age匹配行筛选出来;
在MySql5.6之后,我们通过索引找到name匹配的数据中直接对组合索引里匹配的列进行筛选得到对应的主键id,减少了回表次数,也就是减少了IO操作;