Kafka的消息是如何存储的
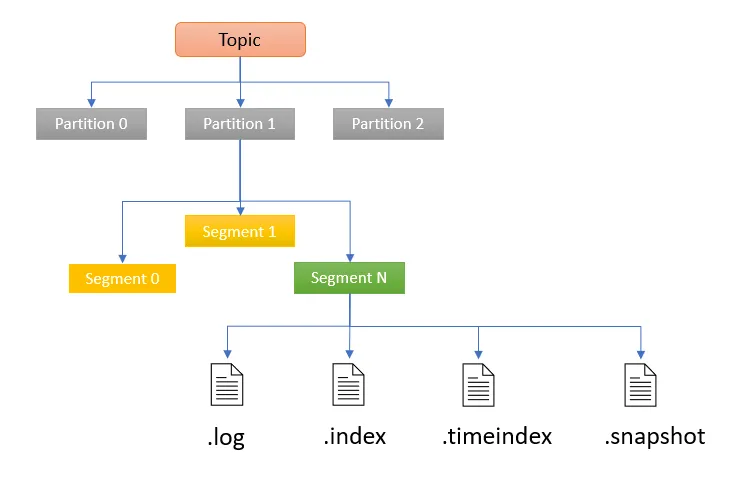
整体结构
Topic(主题):是最顶层的概念,类似于一个消息的类别或频道,是消息的集合。例如,在一个电商系统中,可以有“订单主题”“用户行为主题”等,不同类型的消息会被归类到不同的主题下。
Partition(分区):每个主题可以被划分为一个或多个分区,图中展示了Partition 0、Partition 1、Partition 2。分区主要用于实现数据的并行处理和存储,同一主题下的不同分区可以分布在不同的服务器(broker)上,从而实现水平扩展。比如一个“日志主题”可能有多个分区,大量的日志消息会根据一定规则分配到不同分区,提高处理效率。分区内的消息是有序的,这对于一些需要保证消息顺序的场景很重要。
分区内的结构
Segment(段):分区中的数据进一步划分为多个段,如图中的Segment 0、Segment 1、Segment N。每个段是一个独立的文件(在磁盘上存储),当分区中的消息数据量增加到一定程度(如段文件大小达到阈值或经过一定时间),就会进行滚动更新,开启新段文件存储后续消息。这种划分方式便于数据管理和维护,比如方便进行数据清理、备份等操作。
1 | $ pwd |
段内的文件类型:
以下是对 Kafka 中这些文件的详细解释:
00000000000000000000.index
● 功能:这是一个稀疏索引文件,与对应的 00000000000000000000.log 文件配合使用。
● 工作原理:它不是为分区内的每一条消息都创建索引,而是按照一定的间隔为消息创建索引。该文件存储了消息在 .log 文件中的偏移量(offset)以及该偏移量消息在 .log 文件中的物理位置信息。当需要查找某条消息时,Kafka 首先在 .index 文件中通过二分查找找到小于或等于目标偏移量的最大索引项,然后根据索引项中的物理位置,到 .log 文件中从这个位置开始顺序查找,直到找到目标消息。这样可以在一定程度上提高查找消息的效率,同时避免为每条消息都创建索引而导致的文件过大问题。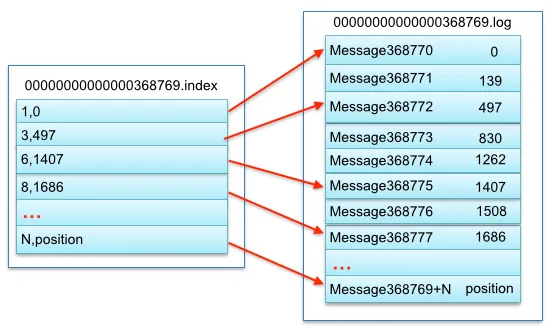
示例:其中以索引文件中元数据 3,497 为例,依次在数据文件中表示第 3 个 message (在全局 partiton 表示第 368772 个 message)、以及该消息的物理偏移地址为497。00000000000000000000.log
● 功能:这是存储实际消息的文件,是分区内消息的主要存储位置。
● 工作原理:当生产者发送消息到 Kafka 分区时,消息会按照一定的顺序存储在这个 .log 文件中。消费者在读取消息时,会从该文件中获取所需的消息内容。根据存储策略,消息会不断追加到该文件中,直到该文件达到一定大小或满足其他条件(如存储时长),此时会创建新的 .log 文件来存储后续的消息。00000000000000000000.timeindex
● 功能:该文件可能是一个时间索引文件,用于根据消息的时间戳来查找消息。
● 工作原理:它可以帮助用户或系统在需要查找特定时间范围内的消息时,根据时间戳快速定位消息所在的位置。它存储了时间戳和相应的消息偏移量或物理位置的对应关系,以便更方便地从 .log 文件中找出特定时间点或时间段内发送的消息,这对于需要按照时间维度来处理消息的场景非常有用,例如监控系统中查找某段时间内的日志记录。leader-epoch-checkpoint
● 功能:该文件主要用于记录分区的领导者(leader)的纪元信息和相应的起始偏移量,以保证数据一致性和故障恢复时的正确处理。
● 工作原理:在 Kafka 集群中,分区会有一个领导者负责处理该分区的读写操作。当领导者发生变化时,这个文件会记录下不同领导者的纪元(epoch)以及在该领导者开始负责时的起始偏移量。这样,在发生故障恢复或副本同步时,副本可以根据该文件的信息确保自己的同步进度正确,避免数据不一致或重复消费的问题。例如,当旧的领导者故障,新的领导者上任,会更新该文件,副本根据新领导者的纪元信息进行数据同步。partition.metadata
● 功能:存储了分区的一些元数据信息。