消费者接入代码实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
@Slf4j
public class OrderConsumer {
public static void main(String[] args) {
Properties kaProperties = new Properties();
kaProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.230:9092");
kaProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kaProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName());
kaProperties.put(ConsumerConfig.GROUP_ID_CONFIG, "order-group");
try (KafkaConsumer<String, Order> consumer = new KafkaConsumer<>(kaProperties)) {
consumer.subscribe(Collections.singletonList("orders"));
while (true) {
ConsumerRecords<String, Order> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, Order> record : records) {
log.info("topic={}, partition={}, offset={}, key={}, value={}",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
} catch (Exception e) {
log.error("Error consuming message", e);
}
}
}
|
消费者poll拉取方法的设计细节
1
2
3
4
|
kaProperties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
...
ConsumerRecords<String, Order> records = consumer.poll(Duration.ofMillis(100));
|
消费者(Consumer)
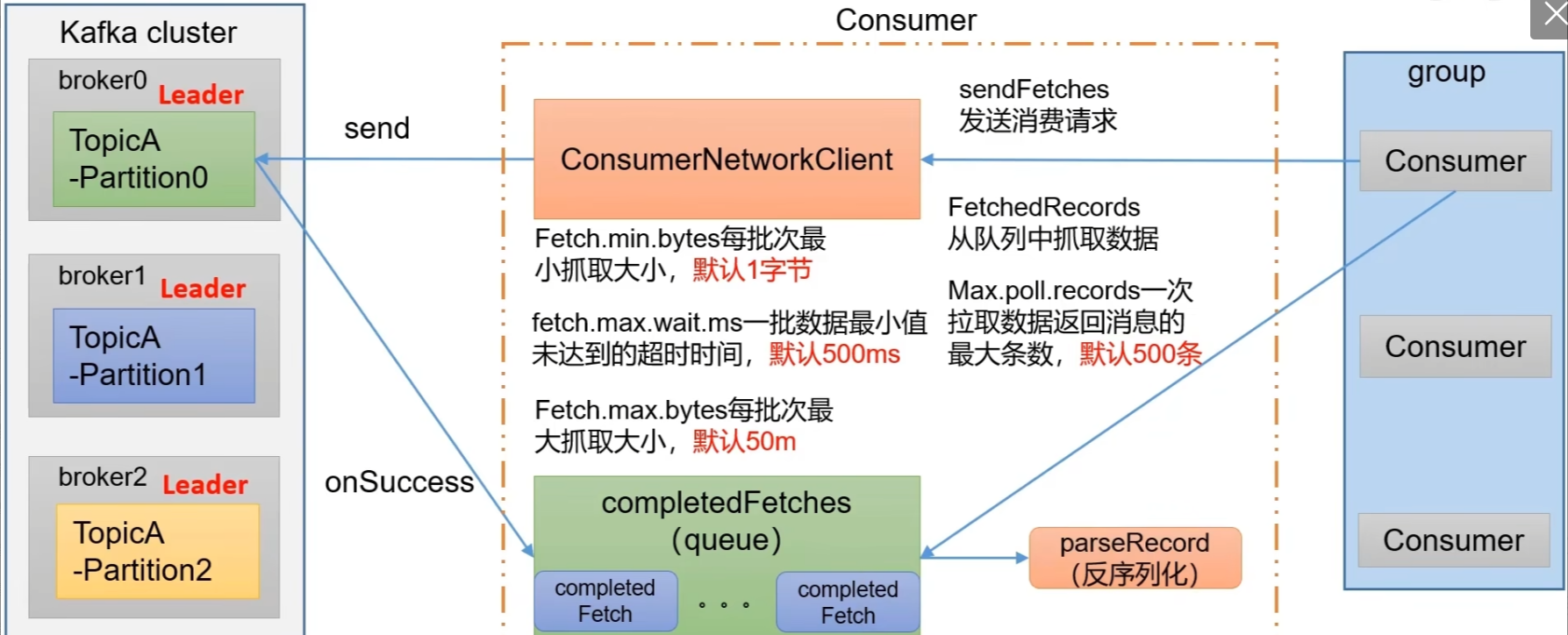
● ConsumerNetworkClient:消费者网络客户端,负责与Kafka集群中的代理节点进行通信。它有几个重要的参数:
○ fetch.min.bytes:每批次最小抓取大小,默认1字节,即每次从代理节点抓取数据时,至少要抓取这么多字节的数据才会返回。
○ fetch.max.wait.ms:一批数据最小值未达到的超时时间,默认500ms,如果在这个时间内没有达到Fetch.min.bytes的要求,也会返回已抓取到的数据。
○ fetch.max.bytes:每批次最大抓取大小,默认50m,即每次抓取数据的最大字节数。
● completedFetches(queue):一个完成抓取的队列,用于存储从代理节点成功抓取到的数据(completed Fetch)。
流程说明
- 消费者通过ConsumerNetworkClient发送消费请求(sendFetches)到Kafka集群中的相应代理节点(根据要消费的主题和分区确定)。
- 代理节点处理请求后,将数据返回给消费者网络客户端。
- 消费者网络客户端将获取到的数据放入completedFetches队列中。
- 消费者从completedFetches队列中抓取数据(FetchedRecords),并进行反序列化( parseRecord)等后续处理。
偏移量初始化
AUTO_OFFSET_RESET_CONFIG 是 Kafka 消费者配置中的一个重要选项,它决定了当消费者启动时,如果没有找到存储的偏移量(例如消费者首次启动或者之前存储的偏移量已过期),该如何确定初始的消费位置。通常有以下几个可能的设置值:
● “earliest”:从最早的可用(未提交)消息开始消费。
● “latest”:从最新的消息开始消费,也就是从分区中当前的末尾位置开始消费,只消费消费者启动后新产生的消息。
● “none”:当设置为 “none” 时,情况有所不同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
@Slf4j
public class OrderConsumer {
public static void main(String[] args) {
Properties kaProperties = new Properties();
kaProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.230:9092");
kaProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kaProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName());
kaProperties.put(ConsumerConfig.GROUP_ID_CONFIG, "order-group");
kaProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
kaProperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
kaProperties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
try (KafkaConsumer<String, Order> consumer = new KafkaConsumer<>(kaProperties)) {
consumer.subscribe(Collections.singletonList("orders"));
while (true) {
ConsumerRecords<String, Order> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, Order> record : records) {
log.info("topic={}, partition={}, offset={}, key={}, value={}",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
} catch (Exception e) {
log.error("Error consuming message", e);
}
}
}
|
消费者自动提交与手动提交
在Kafka中,消费者(Consumers)从主题(Topics)中读取消息。消费者提交(Commit)指的是消费者告知Kafka它已经成功处理了某个偏移量(Offset)之前的所有消息。
consumer_offsets是Kafka内部使用的一个特殊主题,它用于存储所有消费者组的提交偏移量信息。每当消费者提交了新的偏移量(无论是自动还是手动),这个信息就会被记录在 consumer_offsets主题中。Kafka使用该主题来跟踪每个消费者组内各个分区的消费进度,以便在消费者重启或重新平衡时能够从上次提交的位置继续消费消息。
自动提交
自动提交是指Kafka消费者配置为定期自动将已消费的消息偏移量提交给Kafka集群。这种模式简化了编程模型,因为开发者不需要显式地管理偏移量的提交。然而,这也意味着如果消费者在自动提交之后但在处理消息之前崩溃,那么在消费者重启后,它可能会丢失那些尚未处理但已被标记为已处理的消息。
● 优点:易于使用,不需要额外代码来处理偏移量。
● 缺点:可能导致消息丢失,并且难以精确控制何时提交偏移量。
配置参数:
● enable.auto.commit 设置为 true 时启用自动提交。
● auto.commit.interval.ms 定义了两次自动提交之间的间隔时间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
@Slf4j
public class OrderConsumer {
public static void main(String[] args) {
Properties kaProperties = new Properties();
kaProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.230:9092");
kaProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kaProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName());
kaProperties.put(ConsumerConfig.GROUP_ID_CONFIG, "order-group");
kaProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
kaProperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
kaProperties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
try (KafkaConsumer<String, Order> consumer = new KafkaConsumer<>(kaProperties)) {
consumer.subscribe(Collections.singletonList("orders112"));
while (true) {
ConsumerRecords<String, Order> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, Order> record : records) {
log.info("topic={}, partition={}, offset={}, key={}, value={}",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
} catch (Exception e) {
log.error("Error consuming message", e);
}
}
}
|
手动提交
手动提交则要求消费者程序显式地调用提交方法(如 commitSync() 或 commitAsync()),以通知Kafka哪些消息已经被成功处理。这种方式提供了更精细的控制,可以确保只有在消息被成功处理后才提交偏移量,从而避免消息丢失。
● 优点:更好的控制,防止消息丢失。
● 缺点:增加了复杂性,需要开发者正确处理异常情况。
两种主要的手动提交方式:
● commitSync():同步提交,会阻塞直到提交完成或发生错误。如果提交失败,它可以抛出异常,允许应用程序逻辑进行适当的恢复操作。
● commitAsync():异步提交,不会等待提交完成。这对于性能优化很有用,但是如果没有相应的回调机制来处理可能的提交失败,则可能会导致问题。
选择自动提交还是手动提交取决于你的应用需求以及对消息处理保证级别的要求。如果你的应用不能容忍消息丢失并且需要精确一次的处理语义,那么通常应该选择手动提交并谨慎处理偏移量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Collections;
import java.util.Map;
import java.util.Properties;
@Slf4j
public class OrderManualConsumer {
public static void main(String[] args) {
Properties kaProperties = new Properties();
kaProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.230:9092");
kaProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kaProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName());
kaProperties.put(ConsumerConfig.GROUP_ID_CONFIG, "order-group");
kaProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
kaProperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
try (KafkaConsumer<String, Order> consumer = new KafkaConsumer<>(kaProperties)) {
consumer.subscribe(Collections.singletonList("orders"));
while (true) {
ConsumerRecords<String, Order> records = consumer.poll(Duration.ofMillis(100));
if(records.count() > 0){
for (ConsumerRecord<String, Order> record : records) {
log.info("topic={}, partition={}, offset={}, key={}, value={}",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
log.info("Committed offsets: {}", offsets);
if (exception != null) {
log.error("Failed to commit offsets", exception);
}
}
});
}
}
} catch (Exception e) {
log.error("Error consuming message", e);
}
}
}
|