Kafka新高可用架构KRaft
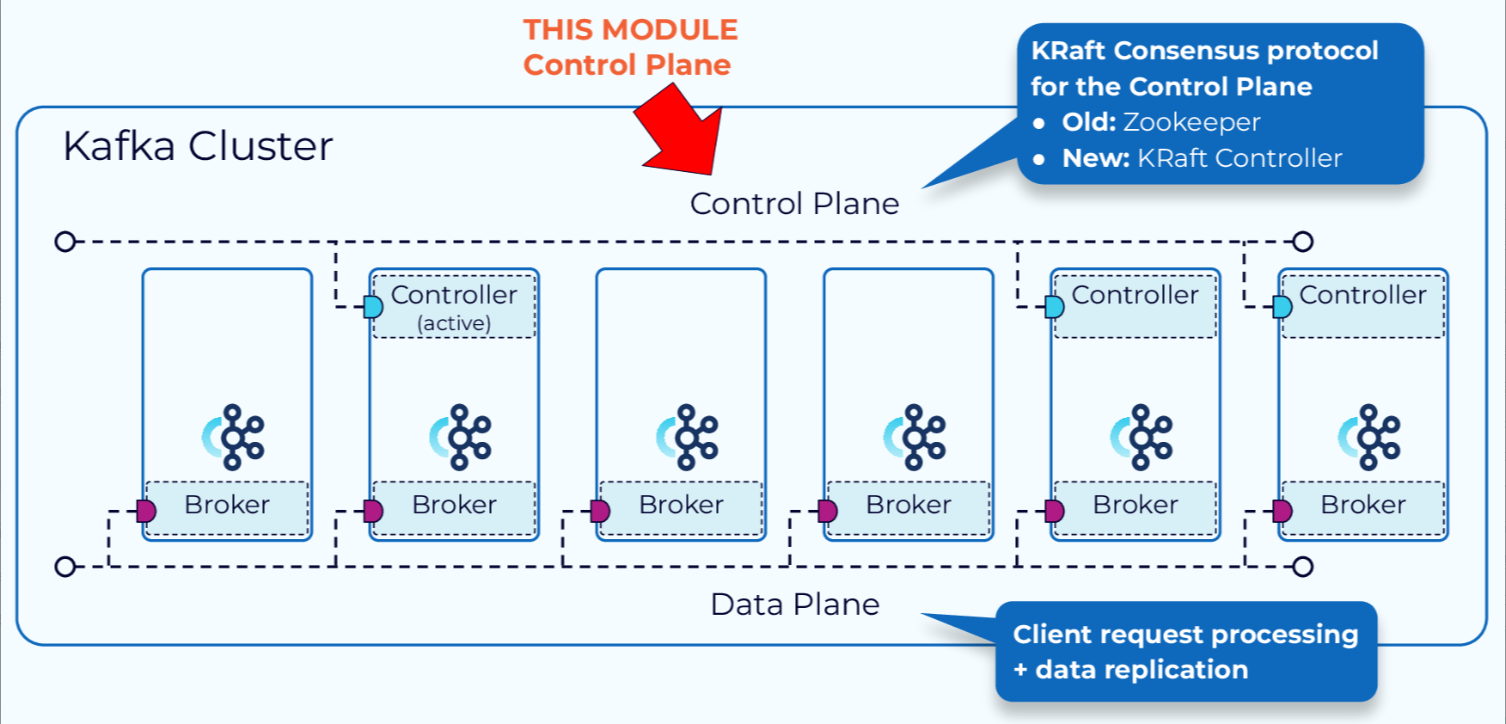
控制平面
ZooKeeper模式
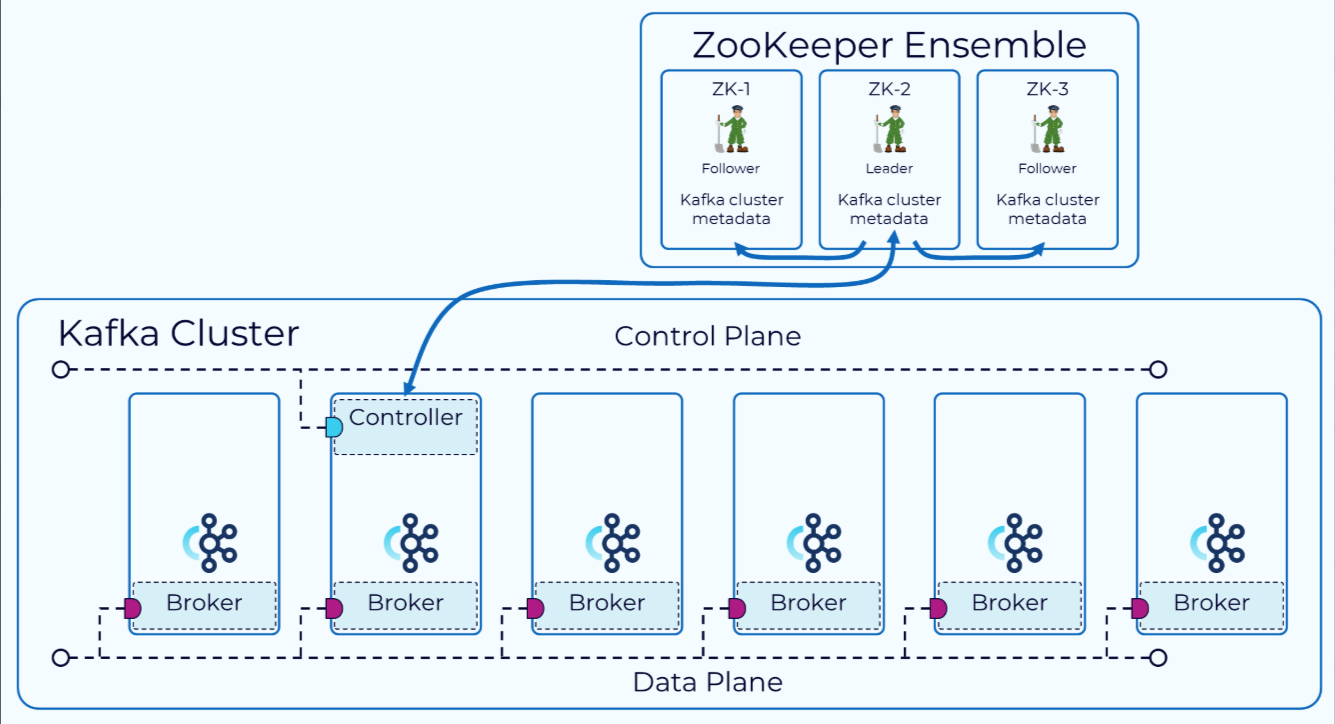
从历史上看,Kafka的控制平面是通过一个名为ZooKeeper的外部共识服务来管理的。其中一个代理被指定为控制器。控制器负责与ZooKeeper以及集群中的其他代理进行通信。集群的元数据持久化存储在ZooKeeper中。
以下是Zookeeper为Kafka保存的一些主要元数据:
- 集群管理信息:包括集群中的所有broker信息,如它们的ID、地址、监听的端口以及它们的状态。
- 主题和分区信息:包括所有主题的列表、每个主题的分区数、每个分区的副本分布情况,以及哪些副本是首领(leader)副本。
- 配置信息:Kafka集群的配置信息,包括各种主题的配置,如副本因子、保留策略等。
- 消费者信息:消费者组的元数据,包括消费者组的成员信息、每个消费者消费的分区信息以及消费偏移量。
- 选举和领导者信息:用于在broker之间进行领导者选举的元数据,以确保集群的可用性和数据的一致性。
- 访问控制列表(ACLs):存储了Kafka的访问控制列表,用于权限管理和安全控制。
- 动态配置:Kafka的动态配置变更也会存储在Zookeeper中,这些配置可以在不重启服务的情况下动态更新。
Controller控制器
Kafka Controller是Apache Kafka集群中的关键组件,其主要作用是在集群的多个broker之间协调和管理操作。
- 领导者选举(Leader Election):在Kafka集群中,每个分区都有一个leader副本和若干个follower副本。Controller负责管理和协调这些副本之间的领导者选举过程。
- 管理分区和副本状态:当集群中的broker启动或关闭时,Controller负责管理分区的状态变更,以及相应副本的状态变更。
- 维护集群元数据:Controller负责维护集群的元数据信息,包括分区信息、副本位置信息等。
- 处理分区重分配:当执行分区重分配操作时,Controller负责协调和管理分区副本在broker之间的移动。
- 处理broker故障:当某个broker发生故障时,Controller负责检测到这一情况,并触发新的领导者选举过程,确保故障brokers上的分区可以快速恢复服务。
- 管理新创建的主题:当在Kafka集群中创建新主题时,Controller负责分配分区副本到各个broker,并初始化相关元数据。
- 处理集群扩展和收缩:当集群需要增加或移除broker时,Controller负责管理相关的元数据和状态变化。
- 同步操作日志:Controller会将操作日志记录到内部主题(consumer_offsets或controller_epoch)中,确保集群状态的一致性和持久性。
Kafka Controller通过这些功能确保了Kafka集群的高可用性和稳定性,使得Kafka能够高效地处理大规模数据流。
KRaft模式
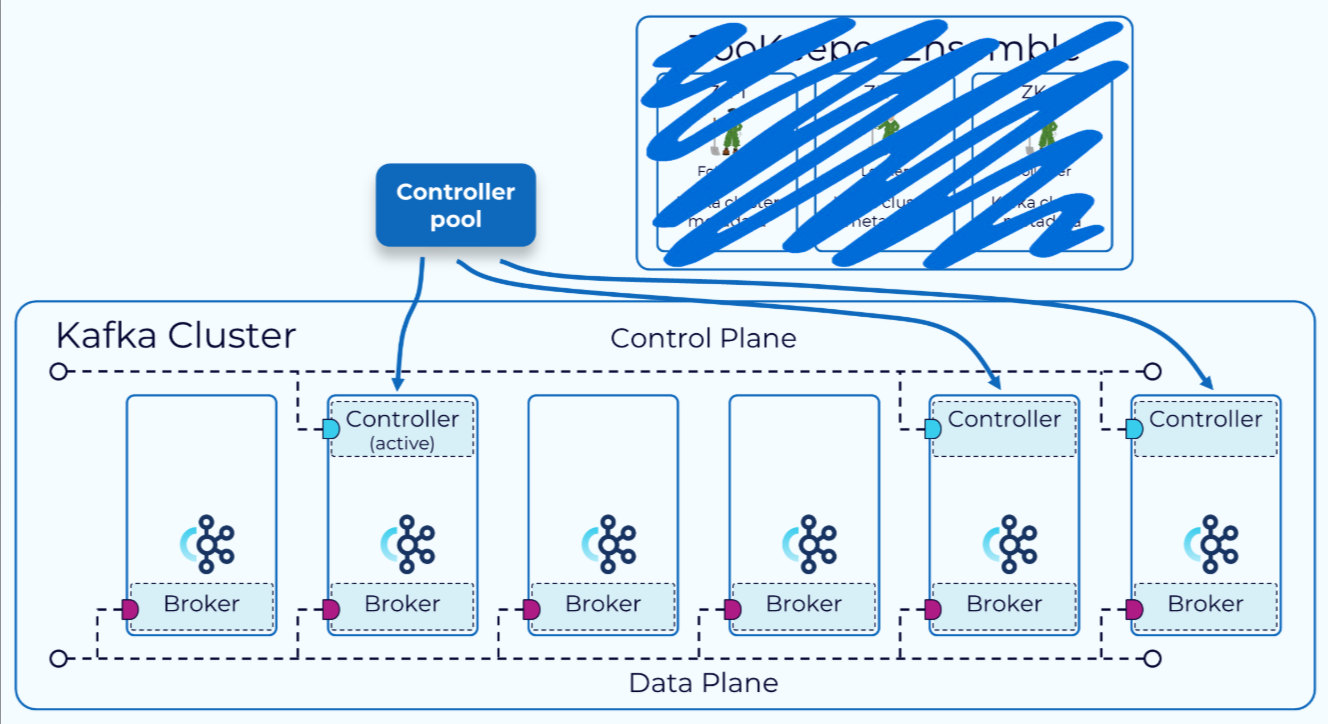
随着2022年10月Apache Kafka 3.3.1版本的发布,一种用于元数据管理的新共识协议——KRaft,已被标记为可用于生产环境。以Kraft模式运行Kafka不再需要为每个Kafka集群额外运行一个ZooKeeper集群。
在KRaft中,一部分代理被指定为控制器,这些控制器提供了以前由ZooKeeper提供的共识服务。现在,所有的集群元数据都存储在Kafka主题中,并在内部进行管理。
KRaft模式的优势
新的KRaft模式有很多优势,这里我们将讨论其中的一些。
● 部署和管理更简单 —— 现在只需要安装和管理一个应用程序,Kafka的运维足迹大大减小。这也使得在边缘的小型设备上更易于使用Kafka。
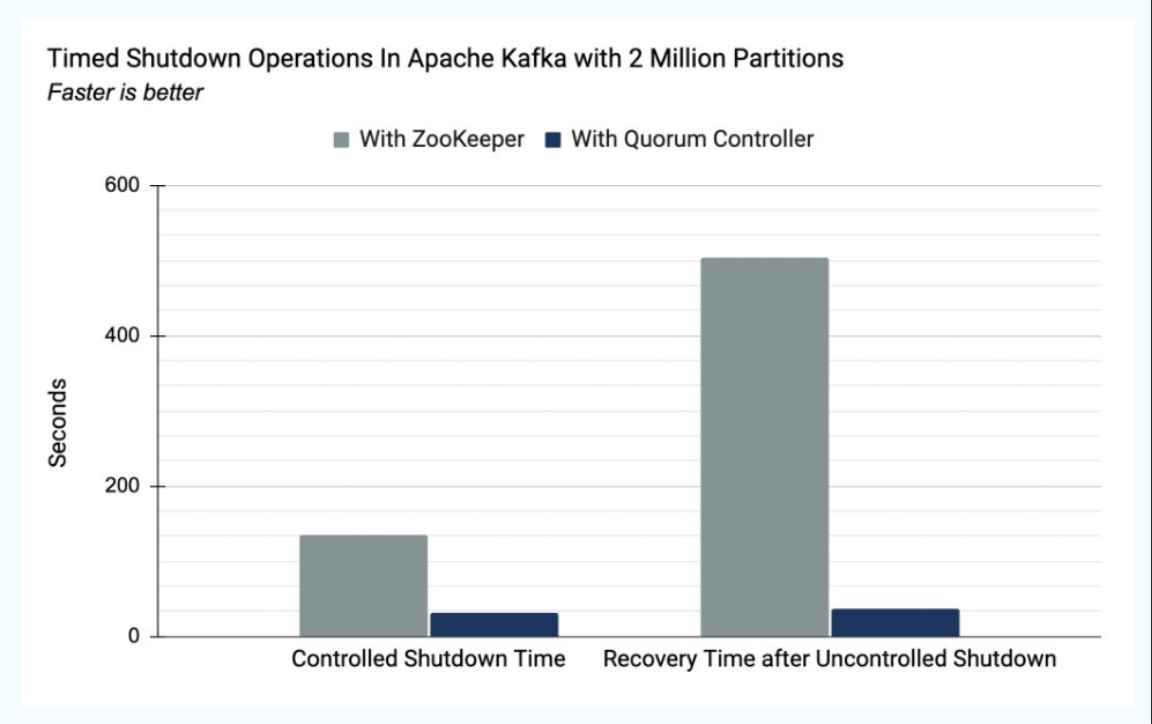
● 可扩展性提高 —— 如图所示,KRaft的恢复时间比ZooKeeper快一个数量级。这使得我们能够在单个集群中高效地扩展到数百万个分区。而使用ZooKeeper时,有效限制在数万个分区。
● 元数据传播更高效 —— 基于日志的、事件驱动的元数据传播提高了Kafka许多核心功能的性能。
KRaft集群节点角色
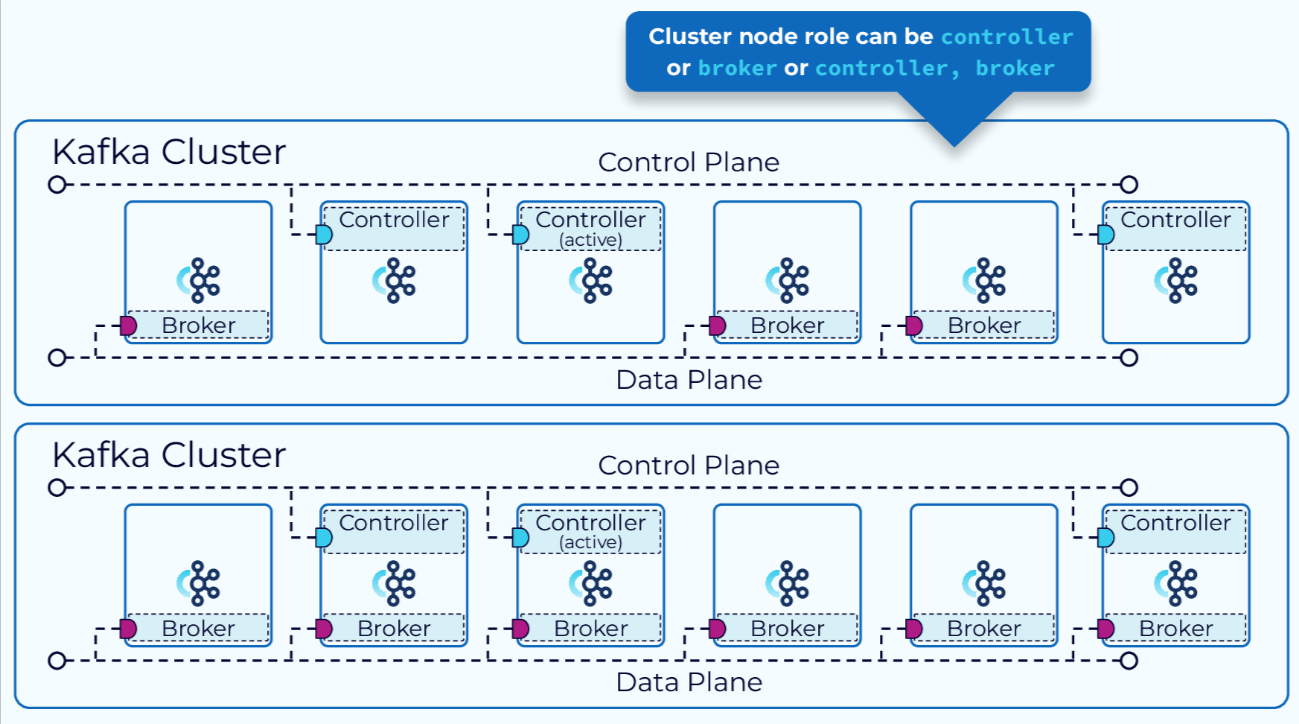
在KRaft模式下,Kafka集群可以以专用模式或共享模式运行。在专用模式下,一些节点的process.roles配置将设置为controller,其余节点将其设置为broker。对于共享模式,一些节点的process.roles将设置为controller, broker,这些节点将承担双重职责。选择哪种模式取决于集群的规模。
KRaft模式控制器
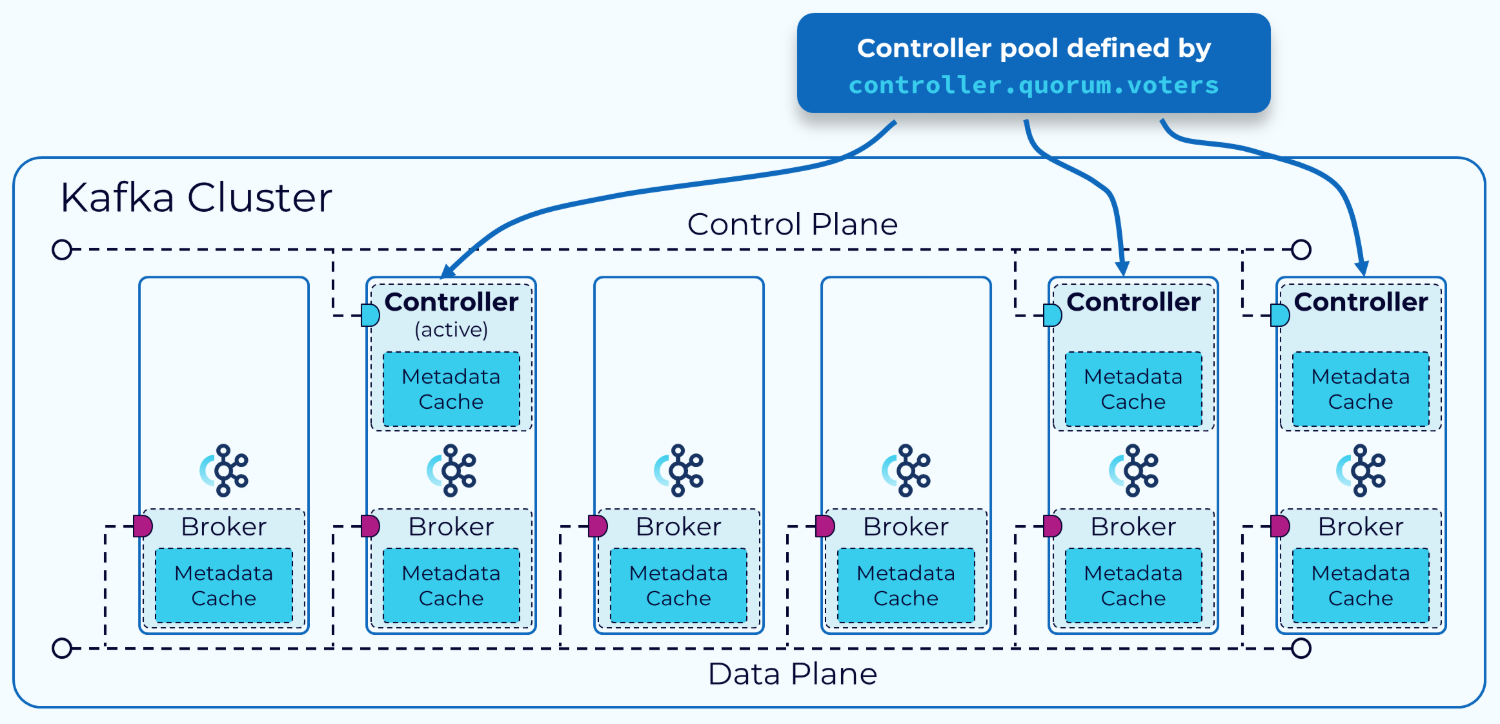
在KRaft模式的集群中,充当控制器的代理列在每个代理上设置的controller.quorum.voters配置属性中。这使得所有代理都能够与控制器进行通信。其中一个控制器代理将成为活动控制器,它将负责与其他代理通信以处理元数据的更改。
所有控制器代理都维护一个内存中的元数据缓存,该缓存会保持更新,以便在需要时任何控制器都可以接管成为活动控制器。这是KRaft的一个特性,使其比基于ZooKeeper的控制平面高效得多。
KRaft集群元数据
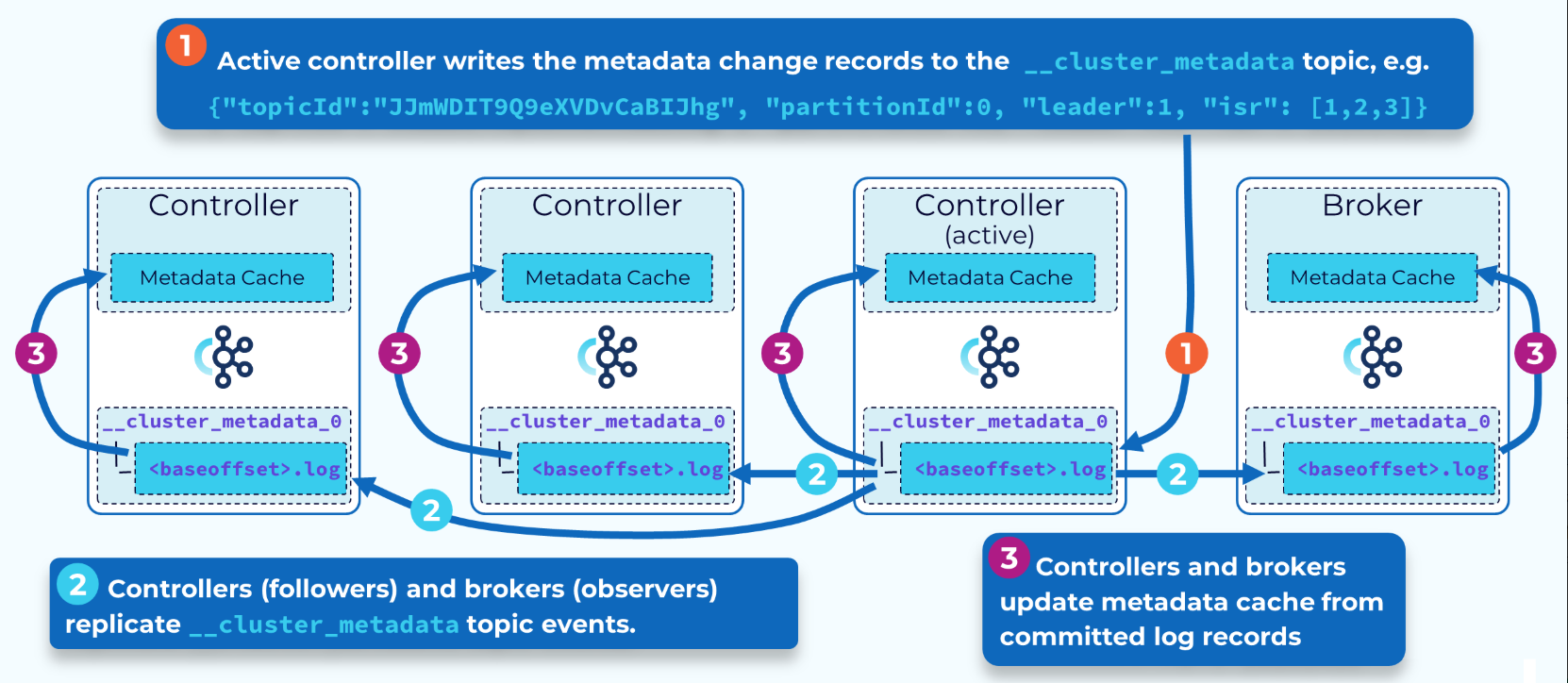
KRaft基于Raft共识协议,该协议作为KIP - 500的一部分引入到Kafka中,其他相关的KIP中定义了更多详细信息。在KRaft模式下,反映所有控制器管理资源当前状态的集群元数据存储在一个名为__cluster_metadata的单分区Kafka主题中。KRaft使用这个主题在控制器和代理节点之间同步集群状态的更改。
活动控制器是这个内部元数据主题的单个分区的领导者。其他控制器是副本跟随者。代理是副本观察者。因此,控制器不是将元数据更改广播给其他控制器或代理,而是由它们各自去获取这些更改。这使得保持所有控制器和代理的同步非常高效,并且还缩短了代理和控制器的重启时间。
KRaft元数据复制
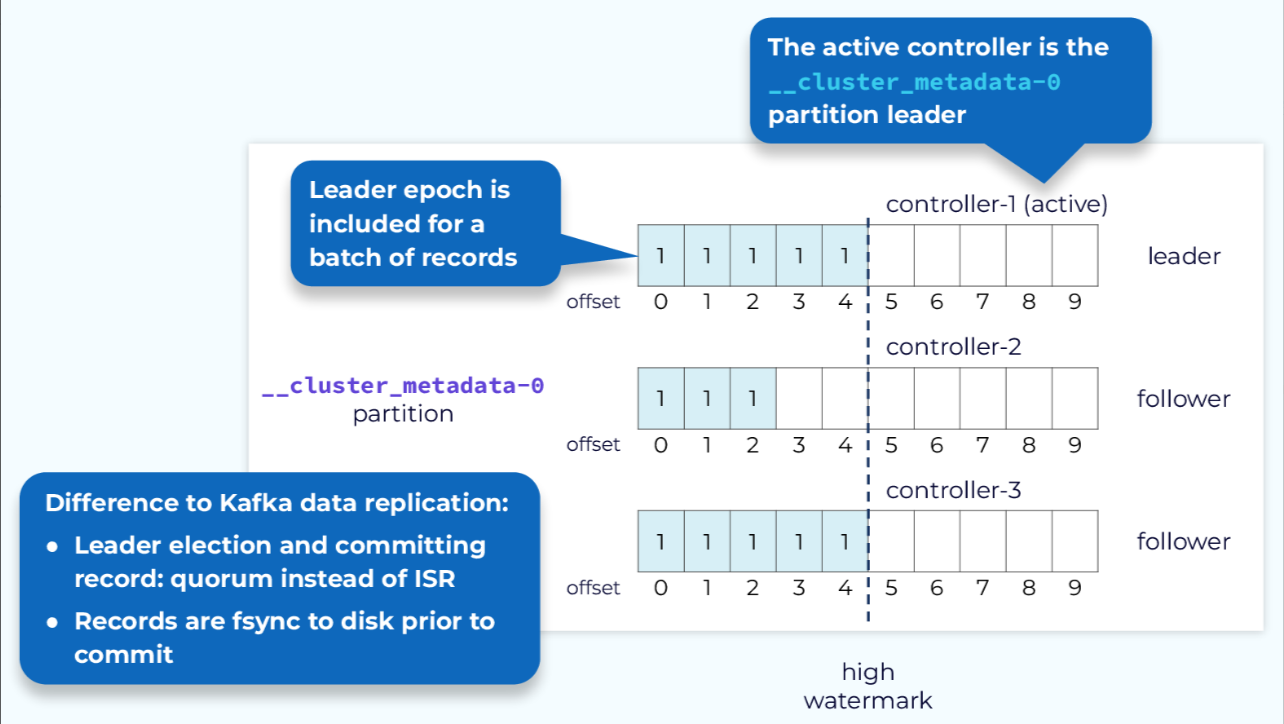
由于集群元数据存储在Kafka主题中,该数据的复制与我们在数据平面复制模块中看到的非常相似。活动控制器是元数据主题的单个分区的领导者,它将接收所有写入操作。其他控制器是跟随者,将获取这些更改。我们仍然像数据平面一样使用偏移量和领导者epoch。然而,当需要选举领导者时,是通过法定人数(quorum)来完成的。另一个区别是,元数据记录在写入每个节点的本地日志时会立即刷新到磁盘。
Controller Leader选举过程
KRaft模式下Controller Leader选举的通俗版
- 初始状态:大家都是小弟(Follower)
● 每个Broker(Kafka服务器)启动时,都是“小弟”(Follower),等着“大哥”(Leader)发号施令。
● 大哥会定期给小弟们发“心跳”(心跳包),告诉大家:“我还活着,继续听我的!”1
2
3Broker 1 (Follower)
Broker 2 (Follower)
Broker 3 (Follower) - 大哥挂了,小弟们开始慌了
● 如果小弟们长时间没收到大哥的心跳,就会觉得:“大哥可能挂了!”
● 这时,小弟们会进入“竞选模式”(Candidate),准备选一个新大哥。1
2
3Broker 1 (Candidate) 👀
Broker 2 (Candidate) 👀
Broker 3 (Candidate) 👀 - 拉票环节:谁能当大哥?
● 每个想当大哥的小弟会给自己加一个“竞选编号”(term),然后向其他小弟拉票:“选我当大哥吧!”
● 其他小弟会根据候选人的“资历”(日志是否够新)来决定是否投票。1
2
3Broker 1 (Candidate) → 发投票请求
Broker 2 (Candidate) → 发投票请求
Broker 3 (Candidate) → 发投票请求 - 投票结果:谁票多谁当大哥
● 如果某个候选人拿到超过一半的票(多数票),就会成为新大哥(Leader)。
● 其他小弟会重新变回小弟(Follower),听新大哥的指挥。1
2
3Broker 1 (Leader) 🎉
Broker 2 (Follower)
Broker 3 (Follower) - 新大哥上任,开始干活
● 新大哥会定期给小弟们发心跳,告诉大家:“我是新大哥,听我的!”
● 新大哥还会检查小弟们的“工作进度”(日志同步),确保大家的数据一致。1
2
3Broker 1 (Leader) → 发心跳
Broker 2 (Follower) ← 收到心跳
Broker 3 (Follower) ← 收到心跳 - 如果又有大哥挂了,重新选
● 如果新大哥也挂了,小弟们会再次进入竞选模式,重复上述过程。
关键点总结
- 多数票原则:必须拿到超过一半的票才能当大哥。
- 日志一致性:只有“资历够深”(日志够新)的小弟才有资格竞选。
- 心跳机制:大哥靠心跳维持地位,小弟靠心跳确认大哥是否活着。