Kafka副本管理与ISR机制解析
Kafka中的主副本(Leader Replica)和备份副本(Follower Replica)的放置是由Kafka集群自动管理的,这个过程与Controller组件密切相关。Controller负责监控集群状态,包括副本的选举和分区的分配。当一个分区的主副本发生故障时,Controller会触发一个新的选举过程,从同一分区的备份副本中选择一个新的主副本。同时,Kafka会根据配置的副本因子(replication factor)和集群的拓扑结构,自动将副本分散到不同的节点上,以实现高可用性和数据冗余。这个过程确保了即使某些节点发生故障,数据仍然可以从其他节点上的副本中恢复,从而提高了系统的容错能力。简而言之,Kafka通过Controller组件和集群的自动管理机制,智能地决定主副本和备份副本的放置,以优化数据的可用性和可靠性。
1 | cat > docker-compose.yaml <<-'EOF' |
1 | [root@docker-vm kafka]# docker exec -it kafka-1 /bin/bash |
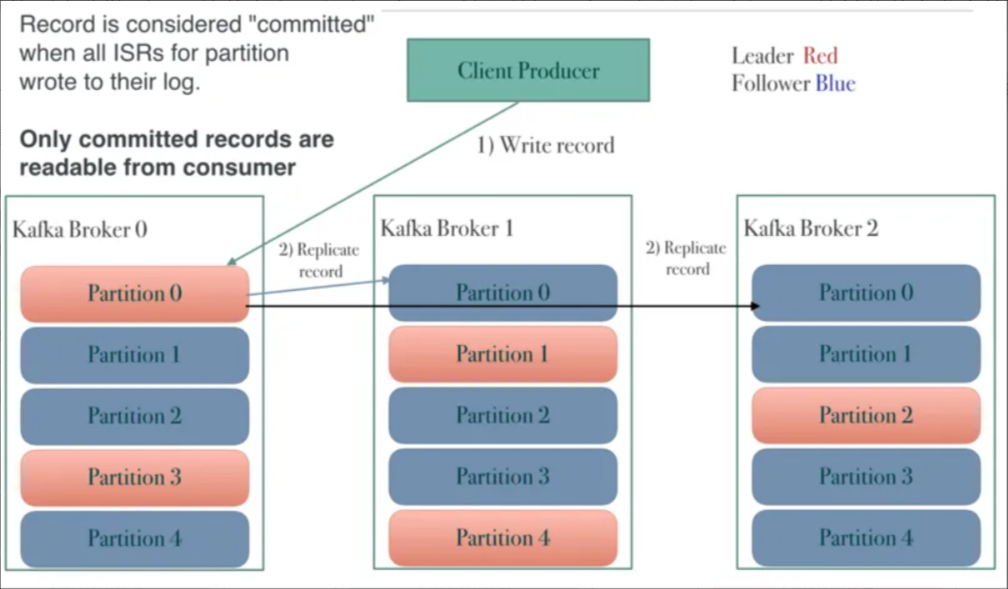
领导者副本负责处理该分区的读写请求,其他副本会从领导者副本同步数据。
- Replicas: 该分区的所有副本所在的Broker ID列表,这里是
3,1,2,表示该分区有3个副本,分别位于Broker 3、Broker 1和Broker 2上。 - Isr: 该分区的同步副本集(In-Sync Replicas),这里是
3,1,2,表示所有副本都与领导者副本保持同步。同步副本是指那些与领导者副本的消息偏移量差距在一定范围内的副本。 - Elr: 预期领导者副本(Expected Leader Replica),这里为空,表示没有相关信息。
- LastKnownElr: 最后已知的预期领导者副本,这里为空,表示没有相关信息。
ISR列表的依据
在Kafka中,ISR(In-Sync Replicas,同步副本集合)列表的确定主要基于副本与领导者副本(Leader Replica)之间的同步状态,当副本不满足上述同步条件时,就可能会被从ISR列表中剔除,具体情况如下:
- 复制延迟过长
如果一个副本由于性能问题、磁盘I/O瓶颈或网络问题等原因,无法及时从领导者副本复制消息,导致其与领导者副本的偏移量差距超过了Kafka配置的replica.lag.time.max.ms(默认值为10000毫秒,即10秒),那么这个副本就会被认为是滞后的,领导者副本会将其从ISR列表中剔除。
例如,由于某个副本所在的节点磁盘性能不佳,无法快速写入复制的消息,导致其复制进度远远落后于领导者副本,当超过了replica.lag.time.max.ms的时间限制后,该副本就会被移除出ISR列表。 - 心跳超时
如果一个副本在一定时间内没有向领导者副本发送心跳请求,领导者副本会认为该副本已经不可用。这个时间限制由replica.lag.time.max.ms参数控制。当副本超过这个时间没有发送心跳时,领导者副本会将其从ISR列表中剔除。
例如,由于网络故障导致某个副本无法与领导者副本进行通信,无法发送心跳请求,当超过replica.lag.time.max.ms的时间后,该副本就会被从ISR列表中移除。 - 副本崩溃或故障
如果副本所在的节点发生硬件故障、软件崩溃或其他异常情况,导致副本无法正常工作,那么该副本会停止复制消息并停止发送心跳请求,领导者副本会将其从ISR列表中剔除。
例如,副本所在的服务器突然断电,副本进程崩溃,无法继续复制消息和发送心跳,领导者副本会检测到这种情况并将该副本从ISR列表中移除。