LangChain4j Easy RAG
RAG流程分为两个不同的阶段:索引和检索。LangChain4j 为这两个阶段提供了相应的工具。
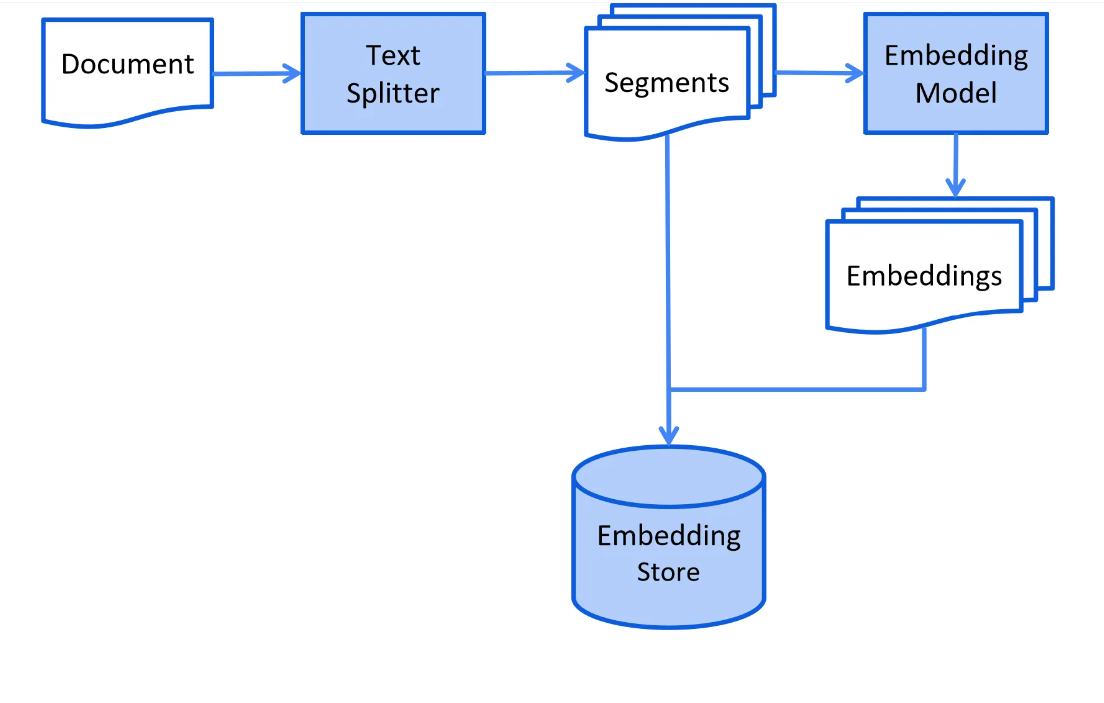
索引阶段
在索引阶段,文档会被预处理,以便在检索阶段进行高效搜索。
这个过程会根据所采用的信息检索方法而有所不同。对于矢量搜索,通常包括以下步骤:清洗文档,添加额外的数据和元数据,将文档分割成小片段(又称分块),嵌入这些片段,并将它们存储在嵌入存储中(又称矢量数据库)。
索引阶段通常是离线的,这意味着用户不需要等待其完成。这可以通过例如每周周末定时任务来重新索引公司文档实现。负责索引的代码也可以是一个独立的应用,专门处理索引任务。
但是,在某些情况下,用户可能需要上传自己的自定义文档,以便LLM可以访问。这种情况下,索引应该在线进行,并且是主应用程序的一部分。
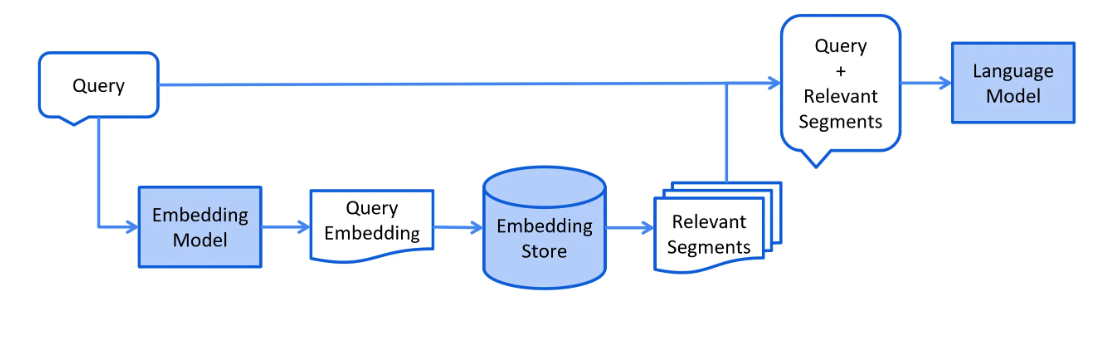
检索阶段
检索阶段通常是在线发生的,当用户提交一个问题,需要使用索引文档来回答时。这个过程可能会根据所使用的信息检索方法而有所不同。对于向量搜索,这通常涉及到对用户的查询(问题)进行嵌入,并在嵌入存储中进行相似度搜索。然后,将相关的片段(原始文档的部分)注入到提示中,并发送给LLM(大型语言模型)。以下是检索阶段的简化流程图:
RAG Flavours in LangChain4j
LangChain4j 提供了三种 RAG 的版本:
● Easy RAG:开始使用 RAG 的最简单方式
● Naive RAG:使用向量搜索实现的基本 RAG 实现
● Advanced RAG:一个模块化的 RAG 框架,允许进行附加步骤,如查询转换、从多个源检索以及重新排序。
Easy RAG
LangChain4j具有“简易RAG”功能,让用户能够轻松上手RAG。用户无需了解嵌入式的概念,选择向量库,寻找合适的嵌入模型,也不需要研究如何解析和分割文档等操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lixiang</groupId>
<artifactId>ex00560</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta3</version>
</dependency>
</dependencies>
</project>
|
1
2
3
4
5
| package com.lixiang;
interface Assistant {
String chat(String userMessage);
}
|
LangChain4j Naive RAG
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lixiang</groupId>
<artifactId>ex00561</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-cohere</artifactId>
<version>1.0.0-beta3</version>
</dependency>
</dependencies>
</project>
|
1
2
3
4
5
| package com.lixiang;
interface Assistant {
String chat(String userMessage);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
| package com.lixiang;
import static dev.langchain4j.data.document.loader.FileSystemDocumentLoader.loadDocuments;
import java.util.List;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.chat.listener.ChatModelErrorContext;
import dev.langchain4j.model.chat.listener.ChatModelListener;
import dev.langchain4j.model.chat.listener.ChatModelRequestContext;
import dev.langchain4j.model.chat.listener.ChatModelResponseContext;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
public class NaiveRagDemo {
public static void main(String[] args) {
Assistant assistant = createAssistant();
String input = "鲁智深做了什么?";
System.out.println("> " + input);
String chat = assistant.chat(input);
System.out.println("< " + chat);
input = "唐僧做了什么?";
System.out.println("> " + input);
chat = assistant.chat("里面的水浒传故事来自于哪个章节?");
System.out.println("< " + chat);
}
private static Assistant createAssistant() {
ChatLanguageModel chatLanguageModel = QwenChatModel.builder()
.apiKey("sk-937aee4c3e654d04b84634d363f5a770")
.modelName("qwen-plus")
.listeners(List.of(chatModelListener()))
.build();
QwenEmbeddingModel embeddingModel = QwenEmbeddingModel.builder()
.apiKey("sk-937aee4c3e654d04b84634d363f5a770")
.modelName("text-embedding-v1")
.build();
List<Document> documents = loadDocuments("D:/Temp/txt");
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
DocumentSplitter splitter = DocumentSplitters.recursive(1000, 0);
documents.forEach(document -> {
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
System.out.println(embeddings.size());
embeddingStore.addAll(embeddings, segments);
});
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(100)
.minScore(0.7)
.build();
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
return AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
}
public static ChatModelListener chatModelListener() {
ChatModelListener listener = new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
System.out.println(">>>>>>>>>>>>>>>>>>>>");
System.out.println("onRequest(): " + requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
System.out.println("<<<<<<<<<<<<<<<<<<<<");
System.out.println("onResponse(): " + responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
System.out.println("onError(): " + errorContext.error());
System.out.println("-------------------");
}
};
return listener;
}
}
|
LangChain4j Advance RAG:查询路由
1
2
3
4
5
| package com.lixiang;
interface Assistant {
String chat(String userMessage);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
| package com.lixiang;
import static dev.langchain4j.data.document.loader.FileSystemDocumentLoader.loadDocuments;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.chat.listener.ChatModelErrorContext;
import dev.langchain4j.model.chat.listener.ChatModelListener;
import dev.langchain4j.model.chat.listener.ChatModelRequestContext;
import dev.langchain4j.model.chat.listener.ChatModelResponseContext;
import dev.langchain4j.rag.DefaultRetrievalAugmentor;
import dev.langchain4j.rag.RetrievalAugmentor;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.rag.query.router.LanguageModelQueryRouter;
import dev.langchain4j.rag.query.router.QueryRouter;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
public class AdvanceRagDemo {
public static void main(String[] args) {
Assistant assistant = createAssistant();
String input = "水浒传中鲁智深做了什么?";
System.out.println("> " + input);
String chat = assistant.chat(input);
System.out.println("< " + chat);
input = "为我介绍下什么是LangChain4j?";
System.out.println("> " + input);
chat = assistant.chat(input);
System.out.println("< " + chat);
}
private static Assistant createAssistant() {
ChatLanguageModel chatLanguageModel = QwenChatModel.builder()
.apiKey("sk-937aee4c3e654d04b84634d363f5a770")
.modelName("qwen-plus")
.listeners(List.of(chatModelListener()))
.build();
QwenEmbeddingModel embeddingModel = QwenEmbeddingModel.builder()
.apiKey("sk-937aee4c3e654d04b84634d363f5a770")
.modelName("text-embedding-v1")
.build();
ContentRetriever fourGreatClassicsRetriever = createFourGreatClassicsRetriever(embeddingModel);
ContentRetriever langChain4jRetriever = createLangChain4jRetriever(embeddingModel);
Map<ContentRetriever, String> retrieverToDescription = new HashMap<>();
retrieverToDescription.put(fourGreatClassicsRetriever, "红楼梦、水浒传、西游记、三国演义节选");
retrieverToDescription.put(langChain4jRetriever, "LangChain4j学习文档");
QueryRouter queryRouter = new LanguageModelQueryRouter(chatLanguageModel, retrieverToDescription);
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryRouter(queryRouter)
.build();
return AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.retrievalAugmentor(retrievalAugmentor)
.build();
}
private static ContentRetriever createFourGreatClassicsRetriever(QwenEmbeddingModel embeddingModel) {
DocumentSplitter splitter = DocumentSplitters.recursive(1000, 0);
List<Document> fourGreatClassicsDocuments = loadDocuments("D:/Temp/txt");
EmbeddingStore<TextSegment> fourGreatClassicsEmbeddingStore = new InMemoryEmbeddingStore<>();
fourGreatClassicsDocuments.forEach(document -> {
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
System.out.println(embeddings.size());
fourGreatClassicsEmbeddingStore.addAll(embeddings, segments);
});
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(fourGreatClassicsEmbeddingStore)
.embeddingModel(embeddingModel)
.maxResults(100)
.minScore(0.7)
.build();
}
private static ContentRetriever createLangChain4jRetriever(QwenEmbeddingModel embeddingModel) {
DocumentSplitter splitter = DocumentSplitters.recursive(1000, 0);
List<Document> langChain4jDocuments = loadDocuments("D:/Temp/langchain4j");
EmbeddingStore<TextSegment> langChain4jEmbeddingStore = new InMemoryEmbeddingStore<>();
langChain4jDocuments.forEach(document -> {
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
System.out.println(embeddings.size());
langChain4jEmbeddingStore.addAll(embeddings, segments);
});
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(langChain4jEmbeddingStore)
.embeddingModel(embeddingModel)
.maxResults(100)
.minScore(0.7)
.build();
}
public static ChatModelListener chatModelListener() {
ChatModelListener listener = new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
System.out.println(">>>>>>>>>>>>>>>>>>>>");
System.out.println("onRequest(): " + requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
System.out.println("<<<<<<<<<<<<<<<<<<<<");
System.out.println("onResponse(): " + responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
System.out.println("onError(): " + errorContext.error());
System.out.println("-------------------");
}
};
return listener;
}
}
|